
Virtualization and the Agile Datacenter

This is the extended version of my presentation for SouthEast LinuxFest 2016. In this presentation, I introduce how virtualization, infrastructure as code, and DevOps enable Agile software development best practices to be applied to network operations. There's a video of the demo embedded towards the end of the page, or you can download the source code and run through it yourself!

Cumulus Networks sells an operating system that runs on switch hardware, but in order to be successful, a company needs to sell more than just a product. It needs to be able to sell a story. When it comes to many of the customers who hear about what we do and reach out to us, there's a common theme in what they are looking for. They've heard about what the major players in the tech industry are doing in their own infrastructure and want to take that home. Automation, replication, virtualization, DevOps, and so on. We don't just sell the operating system, we sell a platform to enable "Web IT" for anyone - big financials or media to small startups.
Some people totally get our value proposition and seek us out, but plenty of potential customers need some convincing that Web IT is the way to go. They may have institutional inertia that is stopping them from adopting new technologies and operational practices, so we need to go further and show how these practices make those major Web IT organizations successful.

I come from the world of software development. Until joining Cumulus, I didn't have any knowledge of networking. So when it comes to articulating the benefits of Web IT over legacy IT, I find it helpful to go back to what I know - software development paradigms. For those who aren't familiar with these, I'm talking about the Waterfall versus the Agile model of software development.
In the Waterfall method, techniques are borrowed from other engineering disciplines, where a project is architected, planned, discussed, and refined well before the first brick hits the foundation. In many engineering disciplines, its very important to plan it right, because once you start building a building or a bridge, you can't just start over again. Failure is expensive, and you don't have the luxury of making mistakes. It makes sense then that software project managers would adopt this mindset for developing software.
However, software is fundamentally different from traditional engineering projects. While oftentimes the blueprint and architectural plan is sufficient to tell if the building is going to meet the customer's requirements, you often don't know if a piece of software is right until it's 90% finished. Unlike a building, however, it's much easier to change direction when developing software since it doesn't have to be built according to the laws of physics. You can replace software components piecemeal, which means that it isn't necessary or even desired to plan the entire project out from the beginning. The Agile method takes advantage of the flexible nature of software.

Most importantly, the Agile method reduces the cost of failure. During development, unexpected problems can come up with the design. Maybe the library or algorithms planned for the project turn out not to work very well in practice. The Agile method gives developers the flexibility to prototype many working solutions to see how well they peform, but also offers an opportunity to to incorporate lessons learned from past "failed" iterations and react to the changing landscape of the target market.
The irony of it all is that people go through the planning of the Waterfall method because they want to reduce the possibilities and impact of failure, but it becomes a self-fulfilling prophecy when they eventually find themselves painted into a corner. The paradox of Agile development (and by extension, DevOps) is that allowing yourself to fail more often improves your chances of success when it matters.

It's for this reason I consider "DevOps" to be the "Agile" of system administration. DevOps is all about adopting best practices from the development world and applying them to the world of operations. One example of this similarity is in the "Infrastructure as Code" pattern that has materialized in the form of automation tools like Puppet, Ansible, and Chef, replacing tribal knowledge and highly specific configuration with generic and abstract reusable templates.
From my interactions with network engineers, they fall squarely in the mindset of people in the Waterfall camp. Which makes sense - for people running the network, failure is not an option. Things like DevOps, taking other people's abstracted source code and applying them to their "unique network" is extremely scary, and the overhead associated with learning a new tool and abstracting out infrastructure may not be worth it. However, these savings are lost when it comes to the time lost when manually reconfiguring equipment from a spreadsheet and onboarding new staff when people holding significant institutional knowledge leave the company. As ops teams become more global, collaboration is even harder when everything is localized for a lab which a remote admin may never see in person.

At the end of the day, Web IT is about building a failure-resilient network so that you can move on without interruptions. You can see this in how the applications and networks are designed: configuration is automated so you can bring factory-reset devices up to speed in no time.
Cheap hardware is used so that you don't have to feel bad about buying a bunch in bulk and hot-swapping it when a device dies. VMs are used so that when services fail, you can just start a whole new machine and worry about the post-mortem later. Finally, since everything is so cheap, you can afford to run replicated clusters of everything, whether it's Cassandra database nodes or multiple spines in a spine-leaf topology. When something inevitably goes down, there's enough surplus capacity that can handle the job until a replacement is deployed


So for a presentation about making failure cheap, I introduce DevOps at a very palatable level for even the most risk-averse network admins. We use a tool called Vagrant to spin up virtual copies of production networks for customers, demos, and even internally for our own networks. We show how to use tools like Ansible to configure a virtual network, even before the equipment they bought arrives at their datacenter. In this environment, they can learn how the tool works, make mistakes, and develop a complete configuration that they can port directly to their production infrastructure. This brings rapid prototyping to a field which traditionally did not have that flexibility.
In other words, make mistakes and work out the bugs in testing so that deployment during scheduled downtime goes smoothly.


One concern I get from a lot of DevOps naysayers is that bootstrapping a virtual testing infrastructure would take too long. When they say that, I immediately ask how long it would take them to get back up and running if all of their devices were wiped clean and all they had were their latest backups. This might be why I don't have very many friends, but at least I know that I can get my production network up in about an hour.
My network is a hybrid cloud setup: I have a bunch of VMs in Google Compute Engine that handle my central SaaS application and my Puppetmaster server. If any of my devices die, I can just spin up a new VM or put a reinstall CD in a hard node and point it to the Puppetmaster. Within thirty minutes, it will be configured good as new. If I lose the Puppetmaster, a full backup of all of my configuration code lives on Github, so I just have to clone the repository and reinstall the Puppetmaster.
One of the first benefits to virtualizating your network is that you operationalize how long it takes you to recover from the worst possible situation. Every time a member of the ops team spins up a fresh simulation, they go through those steps, meaning that when the worst happens, they remain confident that they know what to do to get things working again.
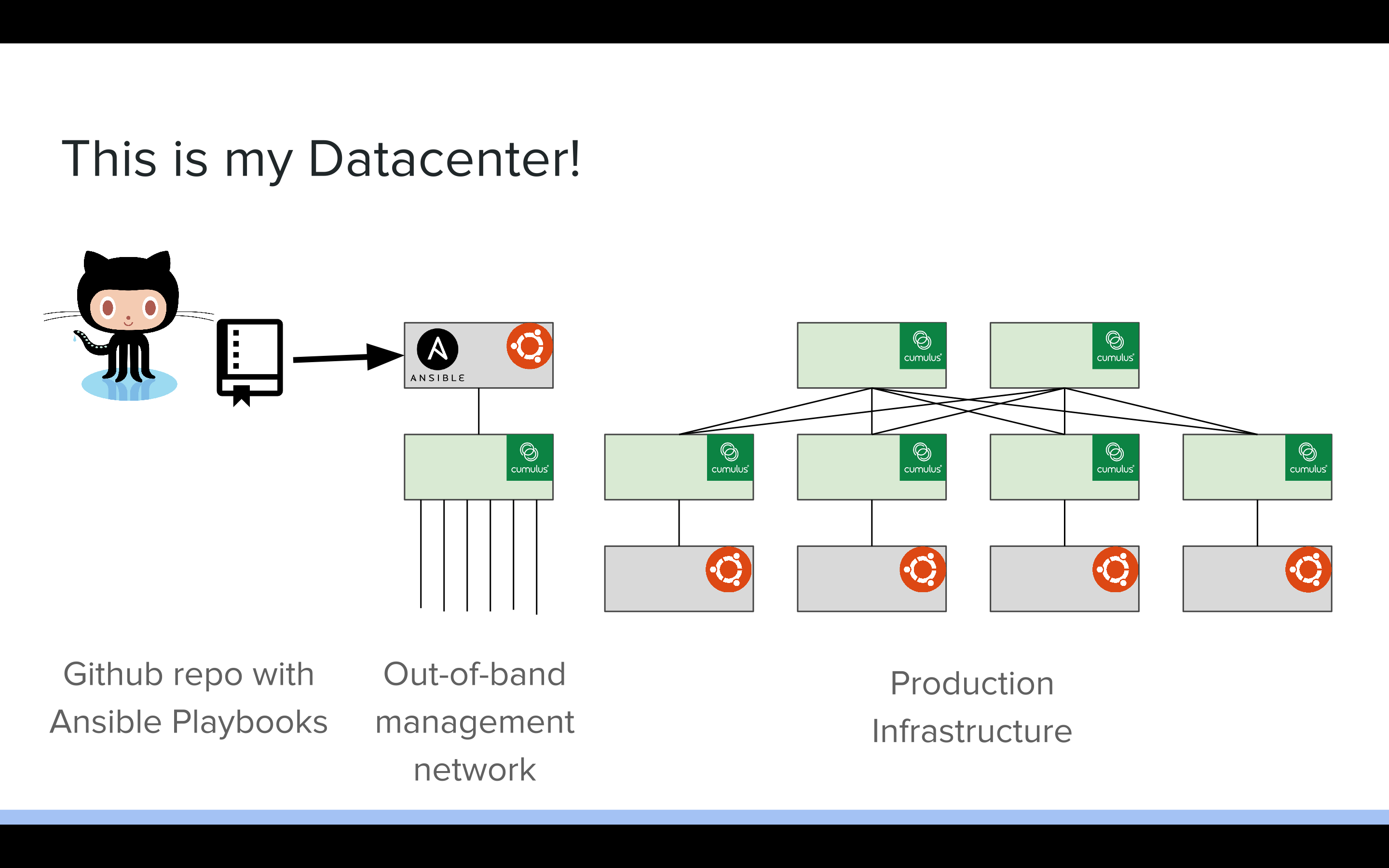
So in this demo, I'm deploying a small spine-leaf CLOS topology. I have two spines with some number of leaves, and an out-of-band management server and switch. My oob-mgmt-server provides DHCP, DNS, and centralized files via HTTP for all of my inband devices. I have all of my configuration saved in an Ansible playbooks stored on Github.

In this demo, I'm leveraging Vagrant to deploy my virtual machines and configure the networking for all of my devices. It takes quite a bit of code to actually wire up the VMs, so we've developed a script called Topology Converter that allows you to generate Vagrantfiles from topology specifications.
We are also using Cumulus VX, a freely available virtual machine that simulates the user experience of using Cumulus Linux. In theory, any configuration that works on VX should work on hardware, with some caveats for highly specific, hardware-dependent features.

Once you have a Vagrantfile that specifies all of the VMs and their connections,
you can use vagrant up to reliably and repeatably provision the
same topology over and over again.

In this demo, the vagrant file that we will be using is available on Github
in the cldemo-vagrant
repository. This repo is actually the reference topology we use for all of
our demos. The second repository,
cldemo-automation-ansible,
is actually downloaded inside of the Vagrant topology after you run
vagrant up.

We will be showing off four cases in our demo. First, we'll bring up the initial, unconfigured topology with Vagrant. This will connect all of the cables to the right ports, but there will be no connectivity between any of the devices. We'll be spinning up a small CLOS topology with two spines, two leaves, and two single-attached servers.

Next we'll download our Ansible playbook from Github and run it. In theory, the Ansible playbook is the same playbook on our production environment, meaning that the playbook is designed to run on physical and virtual equipment with little to no modification. After we run the playbook, BGP unnumbered will be deployed to the fabric, and server01 and server02 will be able to ping each other.

Next, we'll simulate a network failure by destroying spine01, followed by spine02. Watch how the pings between the servers get interrupted when the first spine is destroyed and the network reestablishes connectivity over the other spine. Then, when we destroy the second spine, all connectivity is lost. We'll then show how easy it is to re-run the playbook and get our connectivity back as if nothing had happened.

Finally, we'll show a situation where we are prototyping adding the configuration for a new leaf and server. When I originally made the video, I made a mistake in the configuration and had to reshoot it. However it's great that I made that mistake in a virtual environment instead of learning the hard way with real hardware. Not only is it easy to prototype and test the configuration before pushing it back up to the ground truth, this also shows how easy adding new devices to your network is when you use DevOps tools!
So to wrap things up, here is a video of me running through the four demo scenarios above. You can turn on subtitles to see my commentary, since I recorded this without any audio. I recommend watching it in full screen at max resolution so that you can actually read what's going on in the terminals.

Copyright © 2006-2020 Barry Peddycord III, say hello@isharacomix.org